使用Python爬虫抓取图片和文字实验
本实验指导用户在短时间内,了解和熟悉华为云产品购买及部署操作,并利用华为云服务部署Python爬虫。
1.准备环境
1.1.预置环境
1.3.创建云数据库RDS
在已登录的华为云控制台,展开左侧菜单栏,点击“服务列表”->“数据库”->“云数据库 RDS”进入云数据库RDS控制台。
点击“购买数据库实例”。
① 计费模式:按需计费;
② 区域:华北-北京四;
③ 实例名称:自定义,如rds-spider;
④ 数据库引擎:MySQL;
⑤ 数据库版本:5.7;
⑥ 实例类型:单机;
⑦ 存储类型:SSD云盘;
⑧ 可用区:可用区二;
⑨ 时区:UTC+08:00;
如下图所示:
① 性能规格:通用型,2核 | 4GB;
② 存储空间:40GB;
③ 硬盘加密:不加密;
④ 虚拟私有云:选择预置环境预置的虚拟私有云;
⑤ 内网安全组:选择预置环境预置的内网安全组;
⑥ 数据库端口:默认(3306);
⑦ 设置密码:现在设置;
⑧ 管理员密码:自定义,如:Huawei@123@#(请牢记设置的密码);
⑨ 参数模板:默认;
⑩ 购买数量:1;
⑪ 只读实例:暂不购买;
如下图所示:


参数设置完成点击“立即购买”,确认参数无误后点击“提交”完成购买,点击“返回云数据库RDS列表”可查看到正在创建的云数据库RDS,约等待【4-6分钟】数据库状态变为“正常”,说明数据库创建完成,如下图所示:
若参数配置与实验手册不符,系统将自动清理您创建的资源,由此将导致创建不成功。
1.4.创建数据库及数据库表
点击云数据库RDS“rds-spider”进入详情页,选择左侧栏“连接管理”在右侧“公网连接”下,点击“绑定”弹性公网IP,在弹窗中选中弹性公网IP点击“确定”完成绑定,如下图所示: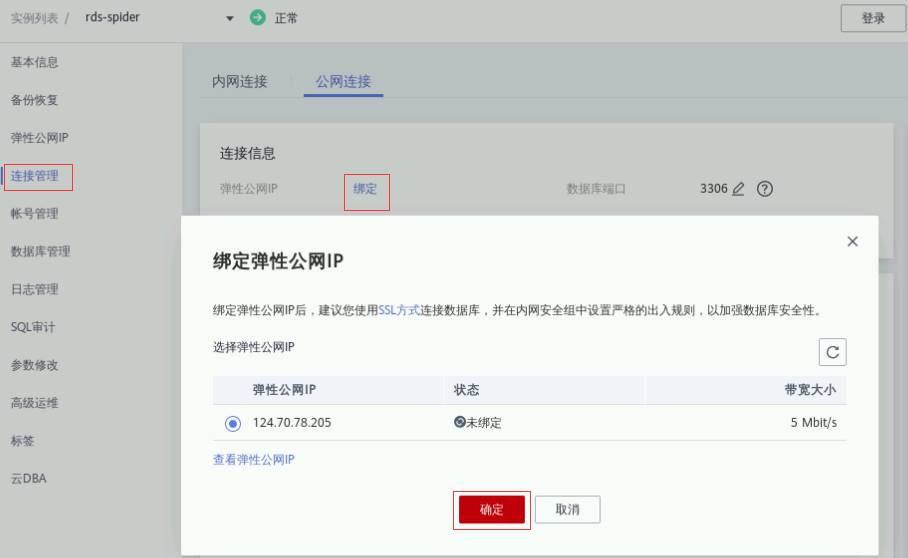
弹性公网IP绑定完成,点击“登录”,输入用户名:root,密码:创建云数据库RDS时设置的密码,如下图所示:

点击“登录”进入数据库列表,然后点击“+新建数据库”,数据库名称为“vmall”,点击“确定”,完成数据库创建,如下图所示:
在新建的数据库右侧点击“新建表”,如下图所示:
进入数据库“vmall”的表管理页,点击“+新建表”,表名:“product”,其他参数默认,点击“下一步”如下图所示:
添加3个字段分别如下:
①列名id,类型int,长度11,勾选主键,扩展信息如下图(id自增长);
②列名title,类型varchar,长度255,勾选可空;
③列名image,类型varchar,长度255,勾选可空。
设置完成点击“立即创建”,弹出SQL预览页面,如下图所示:
点击“执行脚本”完成表创建。
2.查看目的网页并编写爬虫代码
2.1.洞察目的网页
在【实验操作桌面】浏览器新建tab页,输入华为商城地址并访问:https://www.vmall.com/,在打开的页面选择一件商品打开商品详情页,如下图所示:
按“F12”查看网页元素,选择“鼠标跟随”按钮查看元素,然后点击网页中某个元素,可以看到源码界面显示了此元素对应的源码片段,从该源码片段中找到元素class或是id属性,如下图所示:
2.2.创建爬虫项目并导入
切换到【实验操作桌面】,打开“Xfce终端”,依次执行以下命令在桌面新建项目文件夹。
拷贝代码cd Desktop
拷贝代码scrapy startproject vmall_spider
拷贝代码cd vmall_spider
拷贝代码scrapy genspider -t crawl vmall "vmall.com"
执行成功如下图所示:

启动“Pycharm”,启动成功点击“File”->“Open”,选择创建的项目“vmall_spider”如下图所示:

点击“OK”->“This Window”完成项目导入。
2.3.编写爬虫代码
在项目“vmall_spider”->“spiders”下,双击打开“vmall.py”文件,删除原有代码,写入以下代码:
拷贝代码import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from vmall_spider.items import VmallSpiderItem
class VamllSpider(CrawlSpider):
name = 'vamll'
allowed_domains = ['vmall.com']
start_urls = ['https://www.vmall.com/']
rules = (
Rule(LinkExtractor(allow=r'.*/product/.*'), callback='parse_item', follow=True),
)
def parse_item(self, response):
title=response.xpath("//div[@class='product-meta']/h1/text()").get()
price=response.xpath("//div[@class='product-price-info']/span/text()").get()
image=response.xpath("//a[@id='product-img']/img/@src").get()
item=VmallSpiderItem(
title=title,
image=image,
)
print("="*30)
print(title)
print(image)
print("="*30)
yield item
按“Ctrl+s”键保存,如下图所示:
双击打开“itmes.py”文件,删除原有代码,写入以下代码:
拷贝代码# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class VmallSpiderItem(scrapy.Item):
title=scrapy.Field()
image=scrapy.Field()
按“Ctrl+s”键保存,如下图所示:
双击打开“pipelines.py”文件,删除原有代码,写入以下代码(使用步骤1.3创建的云数据库RDS的密码、步骤1.4绑定的弹性公网IP替换代码中的相关信息)。
拷贝代码# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import pymysql
import os
from urllib import request
class VmallSpiderPipeline:
def __init__(self):
dbparams={
'host':'124.70.15.164', #云数据库弹性公网IP
'port':3306, #云数据库端口
'user':'root', #云数据库用户
'password':'Huawei@123@#', #云数据库RDS密码
'database':'vmall', #数据库名称
'charset':'utf8'
}
self.conn=pymysql.connect(**dbparams)
self.cursor=self.conn.cursor()
self._sql=None
self.path=os.path.join(os.path.dirname(os.path.dirname(__file__)),'images')
if not os.path.exists(self.path):
os.mkdir(self.path)
def process_item(self,item,spider):
url=item['image']
image_name=url.split('_')[-1]
print("--------------------------image_name-----------------------------")
print(image_name)
print(url)
request.urlretrieve(url,os.path.join(self.path,image_name))
self.cursor.execute(self.sql,(item['title'], item['image']))
self.conn.commit()
return item
@property
def sql(self):
if not self._sql:
self._sql="""
insert into product(id,title,image) values(null,%s,%s)
"""
return self._sql
return self._sql
替换信息如下图所示,然后按“Ctrl+s”键保存。
鼠标右键“vmall_spider”(目录第二层)点击“new”->“Python File”创建“start.py”文件,填入名称“start”,点击“OK”如下图所示:

写入以下代码。
拷贝代码from scrapy import cmdline
cmdline.execute("scrapy crawl vamll".split())
按“Ctrl+s”键保存,如下图所示:
双击打开“settings.py”文件,删除原有代码,写入以下代码:
拷贝代码# Scrapy settings for vmall_spider project
# python-spider-rds
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
import os
BOT_NAME = 'vmall_spider'
SPIDER_MODULES = ['vmall_spider.spiders']
NEWSPIDER_MODULE = 'vmall_spider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'vmall_spider (+http://www.yourdomain.com)'
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
# COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
# TELNETCONSOLE_ENABLED = False
# Override the default request headers:
# DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
# }
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16'
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# 'vmall_spider.middlewares.VmallSpiderSpiderMiddleware': 543,
# }
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# 'vmall_spider.middlewares.SeleniumDownloadMiddleware': 543,
# }
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
# }
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'vmall_spider.pipelines.VmallSpiderPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
# AUTOTHROTTLE_ENABLED = True
# The initial download delay
# AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
# AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
# AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# HTTPCACHE_ENABLED = True
# HTTPCACHE_EXPIRATION_SECS = 0
# HTTPCACHE_DIR = 'httpcache'
# HTTPCACHE_IGNORE_HTTP_CODES = []
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage
按“Ctrl+s”键保存,部分代码截图如下图所示:
至此代码编写完成。
3.在弹性云服务器ECS上运行爬虫程序
3.1.安装所需依赖
登录弹性云服务器ECS:
① 切换到【实验操作桌面】已打开的“Xfce终端”,执行以下命令(使用弹性云服务器ECS的公网IP替换命令中的【EIP】),登录云服务器;
拷贝代码ssh root@EIP
说明: 在华为云控制点展开左侧菜单栏,点击“服务列表”->“计算”->“弹性云服务器ECS”进入管理列表,可查看复制名称为“python-spider”的ECS服务器的弹性公网IP。
② 接受秘钥输入“yes”,回车;
③ 输入密码:Huawei@123@#(输入密码时,命令行窗口不会显示密码,输完之后直接键入回车)。
登录成功如下图所示:
依次执行以下命令安装所需依赖。
拷贝代码yum -y groupinstall "Development tools"
拷贝代码yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel
安装成功如下图所示:
依次执行以下命令安装依赖。
拷贝代码yum install gcc libffi-devel python-devel openssl-devel -y
拷贝代码yum install libxslt-devel -y
执行成功如下图所示:
执行以下命令升级pip。
拷贝代码pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip
执行成功如下图所示:
依次执行以下命令安装pip依赖。
拷贝代码pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
拷贝代码pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium
拷贝代码pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple pymysql
拷贝代码pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple pillow
执行成功依次如下图所示:



3.2.上传爬虫项目并运行
执行以下命令退出弹性云服务器ECS登录状态。
拷贝代码exit
如下图所示:
执行以下命令(使用弹性云服务器ECS的弹性公网IP替换命令中的EIP)上传项目到弹性云服务器ECS,提示输入密码为“Huawei@123@#”。
拷贝代码cd /home/user/Desktop && scp -r ./vmall_spider root@EIP:/root
完成上传操作,如下图所示:
仿照步骤3.1重新登录弹性云服务器ECS,登录成功后执行以下命令,可查看到上传的项目。
拷贝代码ls
如下图所示:
执行以下命令启动爬虫项目,运行片刻(约30秒),按“Ctrl+Z”键停止运行程序。
拷贝代码cd /root/vmall_spider/vmall_spider/ && python3 start.py
运行成功如下图所示:
3.3.查看爬取数据
切换至【实验操作桌面】浏览器已登录云数据库RDS页面,点击“对象列表”->“打开表”如下图所示:
可看到已爬取的数据,如下图所示:
4.存储爬取图片至对象存储服务OBS
4.1.创建对象存储服务OBS
切换至弹性云服务器列表页,展开左侧菜单栏,点击“服务列表”->“存储”->“对象存储服务OBS”进入管理列表。点击“创建桶”填写参数如下:
① 区域:华北-北京四;
② 数据冗余存储策略:单AZ存储;
③ 桶名称:自定义,如obs-spider;
④ 存储类别:标准存储;
⑤ 桶策略:私有;
⑥ 默认加密:关闭;
⑦ 归档数据直读:关闭;
其他参数默认,如下图所示:

点击“立即创建”->“确定”完成对象存储服务OBS桶的创建,如下图所示:
4.2.安装对象存储服务OBS客户端
在弹性云服务器ECS上安装对象存储服务OBS客户端。
切换至已登录弹性云服务器ECS的命令行界面,执行以下命令下载“obsutil”工具。
拷贝代码cd ~ && wget https://sandbox-experiment-resource-north-4.obs.cn-north-4.myhuaweicloud.com/python-spider-rds/obsutil_linux_amd64.tar.gz
下载成功如下图所示:
执行以下命令解压“obsutil”工具。
拷贝代码tar zvxf obsutil_linux_amd64.tar.gz
解压成功如下图所示:
切换至实验浏览器华为云控制台页面,在右上角账号名下拉菜单中选择“我的凭证”->“访问秘钥”,进入创建管理访问密钥(AK/SK)的界面。位置如下图所示:
请删除原有的访问密钥,再进行新密钥的创建。点击“新增访问密钥”,输入密码(上方系统分配的华为云实验账号的密码)点击“确定”,然后点击“立即下载”选择“保存文件”->“确定”, 将密钥保存至浏览器默认文件保存路径/home/user/Downloads/,妥善保存系统自动下载的“credentials.csv”文件中的AK(Access Key Id)和SK(Secret Access Key)以备后面操作使用。
AK和SK查看方式:
切换至【实验操作桌面】双击图标“Xfce 终端”新打开一个命令行界面,输入以下命令,切换到目录(/home/user/Downloads/)下。
拷贝代码cd /home/user/Downloads/
输入以下命令,即可查看AK和SK内容:
拷贝代码vi credentials.csv
内容如图所示:
切换到已登录弹性云服务器ECS的命令行界面,执行以下命令(使用上图所示AK、SK替换命令中的“your_ak”、“your_sk”),初始化“obsutil”。
拷贝代码./obsutil_linux_amd64_5.2.5/obsutil config -i=your_ak -k=your_sk -e=https://obs.cn-north-4.myhuaweicloud.com
初始化成功如下图所示:
执行以下命令查看“obsutil”连通性。
拷贝代码./obsutil_linux_amd64_5.2.5/obsutil ls -s
连通正常如下图所示:
4.3.上传爬取图片至对象存储服务OBS并查看
继续执行以下命令【使用创建的对象存储服务OBS的名称(如:obs-spider)替换命令中的“your_bucket_name”】,上传爬取到的图片。
拷贝代码/root/obsutil_linux_amd64_5.2.5/obsutil cp /root/vmall_spider/images obs://your_bucket_name -f -r -vmd5 -flat -u
执行成功如下图所示:
仿照4.1步骤找到创建的对象存储服务OBS,点击名称打开详情页,点击左侧栏“对象”可看到上传保存的爬取图片,如下图所示:
任意点击图片名称进入详情,选择“图片预览”可预览爬取的图片如下图所示:
至此试验全部完成。纠错使用Python爬虫抓取图片和文字实验

