云原生数据湖MRS(MapReduce Service)为客户提供Hudi、ClickHouse、Spark、Flink、Kafka、HBase等Hadoop生态的高性能大数据组件,支持数据湖、数据仓库、BI、AI融合等能力。MRS同时支持混合云和公有云两种形态:混合云版本,一个架构实现离线、实时、逻辑三种数据湖,以云原生架构助力客户智能升级;公有云版本,协助用户快速构建低成本、灵活开放、安全可靠的一站式大数据平台。
2.1.进入集群创建界面
进入华为云控制台,鼠标移动到云桌面浏览器页面中左侧菜单栏,点击服务列表->“大数据”->“MapReduce服务 MRS”,进入后点击左侧栏“集群列表”,打开如下图所示:

2.2.创建集群
点击左侧栏“现有集群”,单击右上角“购买集群”,选择“快速购买”并按下图配置参数。

具体参数如下:
区域:华北-北京四
计费模式:按需计费
集群名称:mrs_test
版本类型:普通版
集群版本:MRS 3.1.2.1.T19
组件选择:Hadoop分析集群
可用区:默认
虚拟私有云:vpc-mrs
子网:subent_mrs
集群节点:默认
Kerberos认证:不开启
用户名:root/admin
密码:Mrstest@123
通信安全授权:确认授权



点击下方“立即购买”,此时返回至集群列表界面,可以查看到已经创建的集群。

2.3.绑定弹性公网IP
选择“服务列表-计算-弹性云服务器ECS”,进入ECS控制台,此时可以看到通过集群创建好的五台ECS,接着找到命名为“…master1”的主用ECS。

此时找到右侧“更多-网络设置-绑定弹性公网IP”,将系统预置的弹性公网IP绑定到对应ECS。

此处选择两个预置弹性公网IP中,带宽为100 Mbit/s的EIP进行绑定。

绑定完成后,可以发现详情界面发生改变,此时能够看到主用ECS已显示有刚刚绑定的弹性公网IP。

2.4.配置安全组规则
返回MRS集群列表界面,点击集群名称进入详情界面。


此时找到“IAM用户同步”,点击“同步”按钮,等待同步完成。

同步完成后,可以看到界面已经发生改变。

此时点击“前往Manager”按钮,为集群绑定公网IP和安全组。


绑定成功后,即可进入“Manager”界面。
此时点击“添加安全组规则”,之后选择“管理安全组规则”。

选择“入方向规则”,点击“添加规则”,放通22端口和9022端口,为之后通过远程登录的方式进入ECS做好准备,具体配置如下图:


此处放通的0.0.0.0/0网段只用于实验使用,在实际生产中不建议使用该网段,该网段为全放通状态,有一定安全隐患,故仅限实验测试使用。
安全组配置完成后,返回绑定界面,点击“确定”,此时会自动跳转至“Manager”界面。



输入之前创建MRS集群所设置的用户名“admin”和密码即可进入。

2.5.Hive创建表
Hive是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive定义了简单的类SQL查询语言,称为HiveQL,它允许熟悉SQL的用户查询数据。Hive的数据计算依赖于MapReduce、Spark、Tez。
此时进入ECS控制台,找到主用ECS“master1”,查看对应弹性公网IP并复制。
接着通过虚拟桌面中的Xfce终端登录ECS“master1”,具体操作如下(登录密码为创建MRS集群时所设置的集群密码):


通过如下命令登录至ECS,
ssh root@弹性公网IP

(若是出现提示,选择yes进入下一步,输入密码完成登录)

2.5.1.创建内部表
首先设置环境变量,输入以下命令实现:
source /opt/client/bigdata_env

输入:beeline,回车进入hive;
注意:hive中的所有语句都需要以分号结尾,否则不能执行。

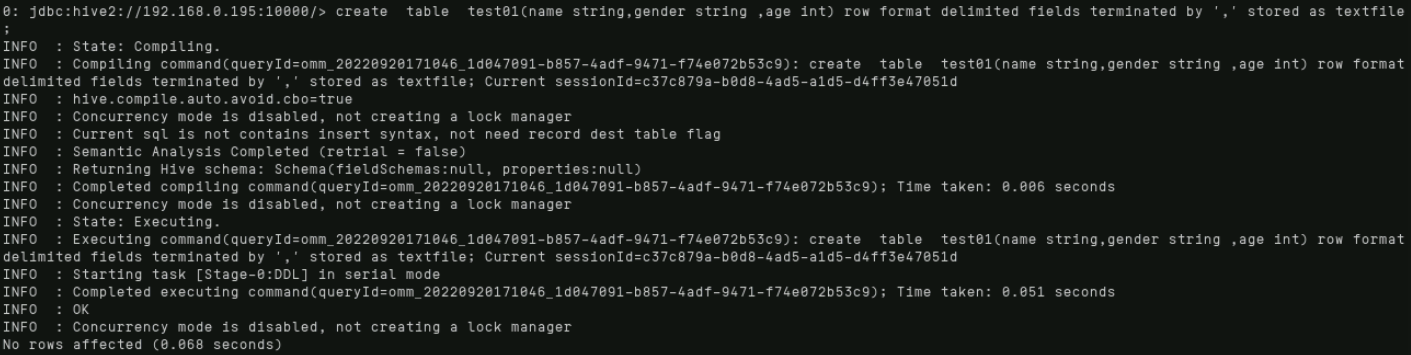
输入以下命令创建内部表:
create table test01(name string,gender string ,age int) row format delimited fields terminated by ',' stored as textfile ;
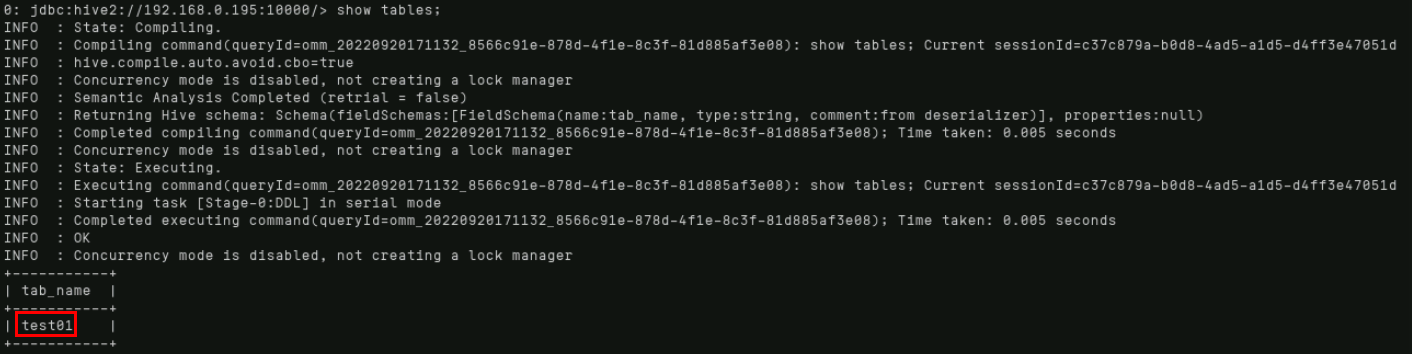
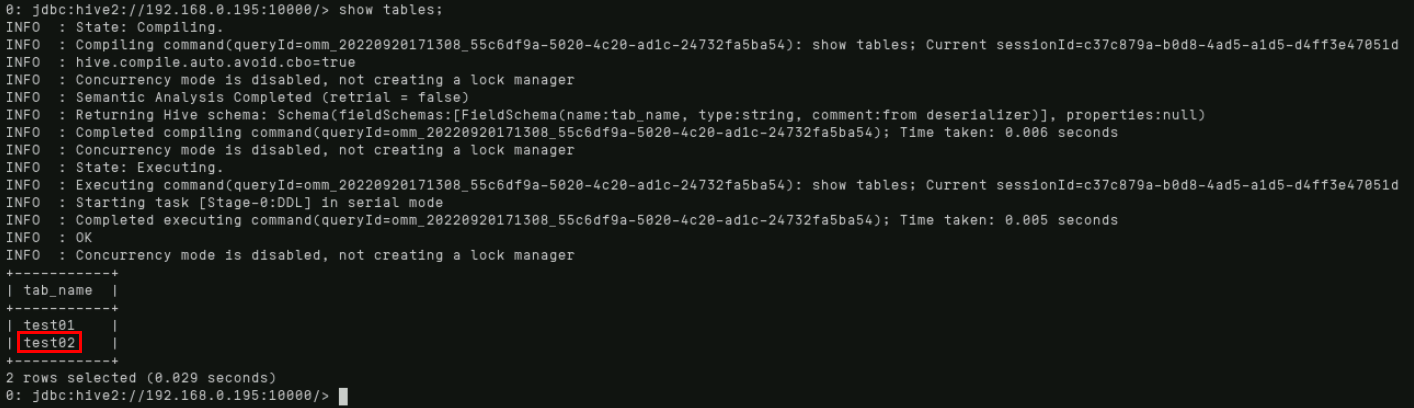
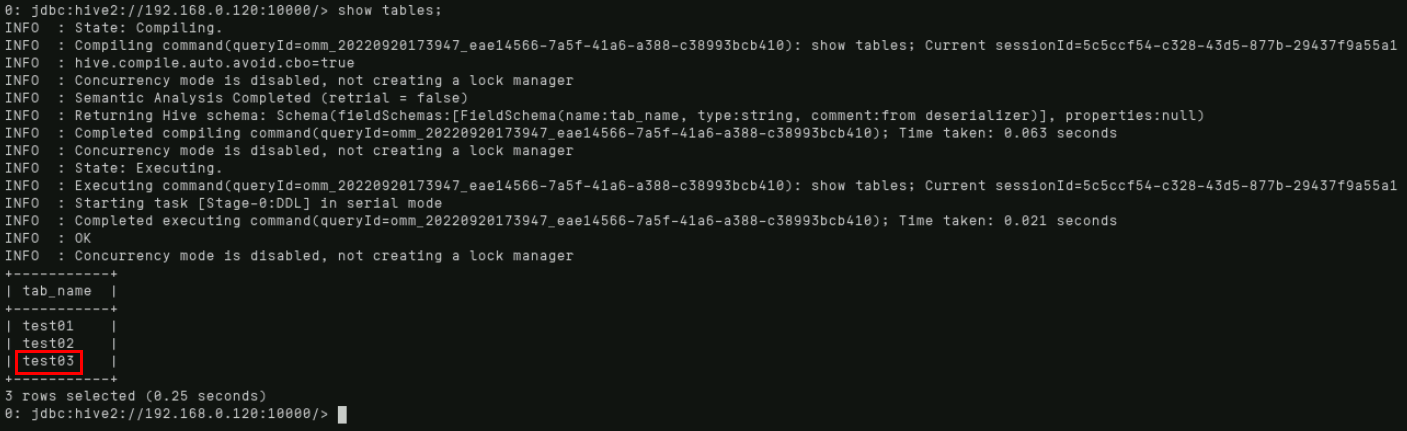
通过“show tables;”命令显示所有已存在的表。
2.5.2.创建外部表
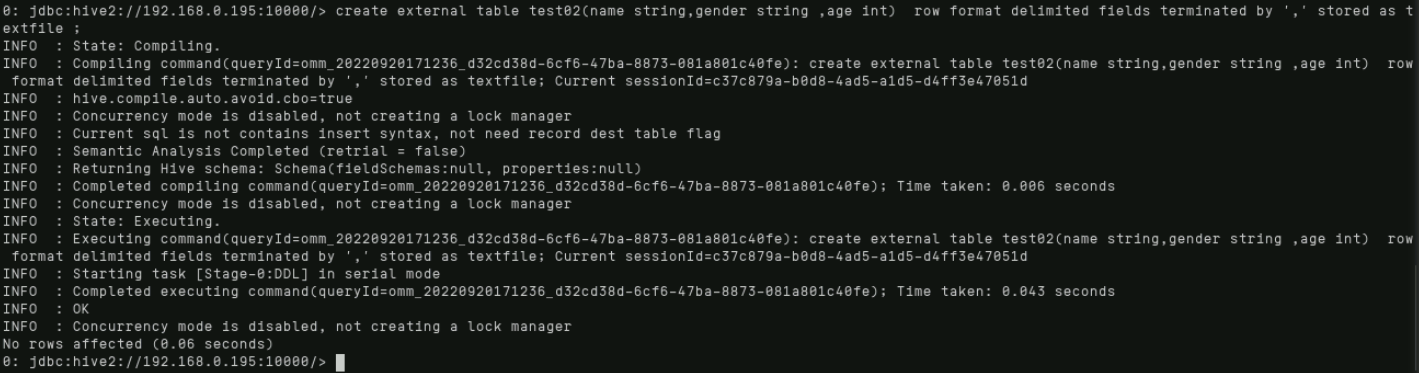
输入以下命令创建外部表:
create external table test02(name string,gender string ,age int) row format delimited fields terminated by ',' stored as textfile ;
2.5.3.载入HDFS数据
HDFS是Hadoop的分布式文件系统(Hadoop Distributed File System),实现大规模数据可靠的分布式读写。HDFS针对的使用场景是数据读写具有“一次写,多次读”的特征,而数据“写”操作是顺序写,也就是在文件创建时的写入或者在现有文件之后的添加操作。HDFS保证一个文件在一个时刻只被一个调用者执行写操作,而可以被多个调用者执行读操作。
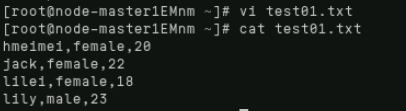
首先通过“ctrl+c”退出hive模式(或者新打开一个窗口),此时编辑名为test01.txt的数据文件,具体编辑内容如下:
此时使用命令“source /opt/client/bigdata_env”设置HDFS环境变量。
source /opt/client/bigdata_env

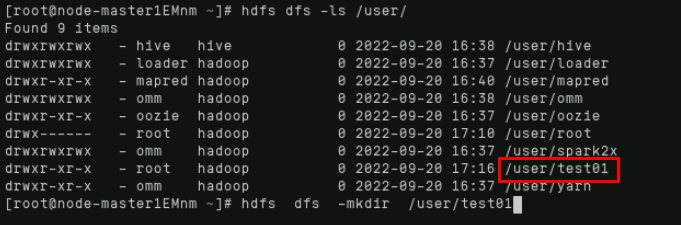
在根目录的user文件夹下创建test01文件夹,首先查看user下的内容,然后创建,再使用ls命令查看,可以看到出现了test01文件夹。
具体命令:
hdfs dfs -mkdir /user/test01
hdfs dfs -ls /user/
执行hdfs的put命令,把刚刚编辑的数据文件上传到hdfs上的/user/test01/目录中。
命令为:
hdfs dfs -put test01.txt /user/test01/

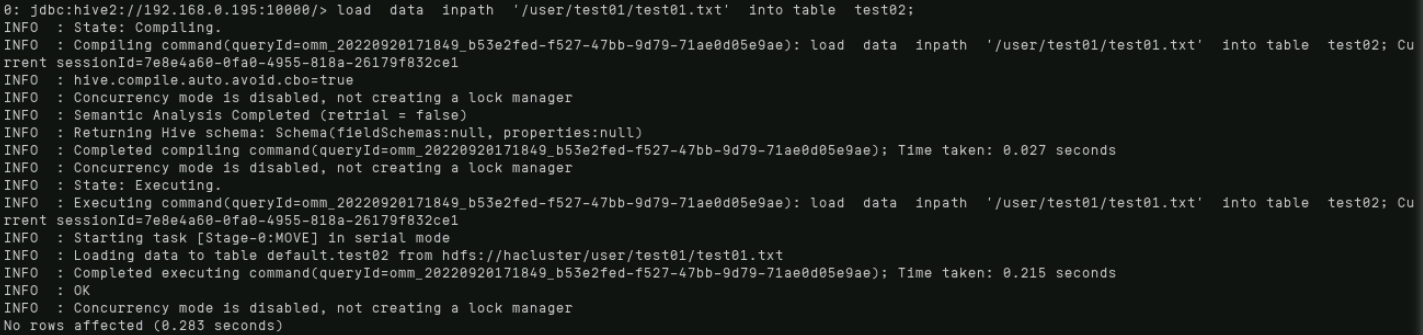
输入beeline进入hive,执行数据加载,导入数据到外部表中,命令:
load data inpath '/user/test01/test01.txt' into table test02;
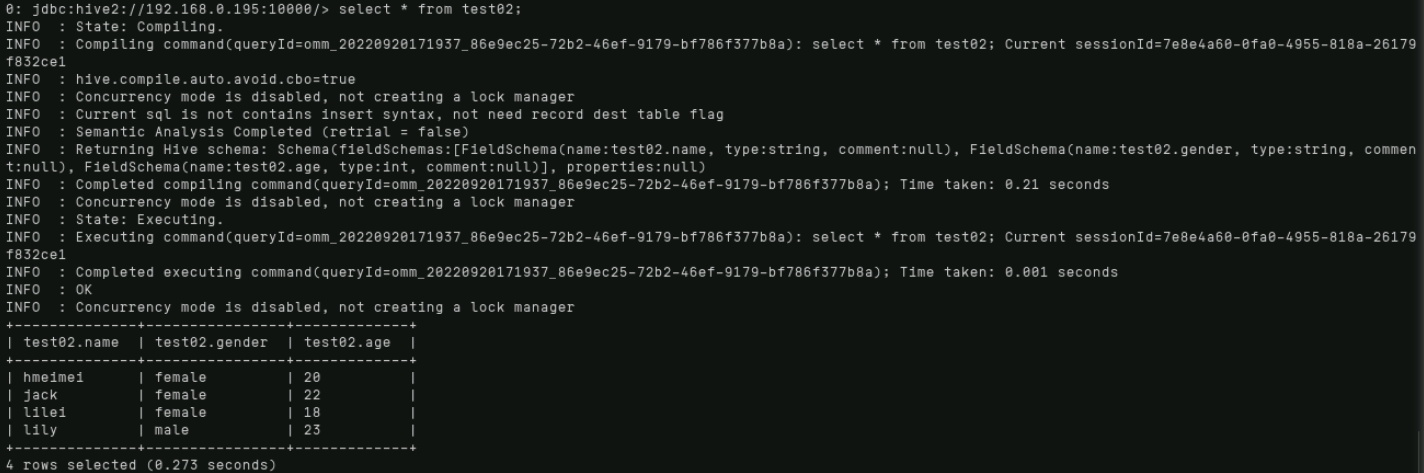
select * from test02;
2.6.Hive查询
2.6.1.模糊查询表
执行命令:
show tables like 'test*';
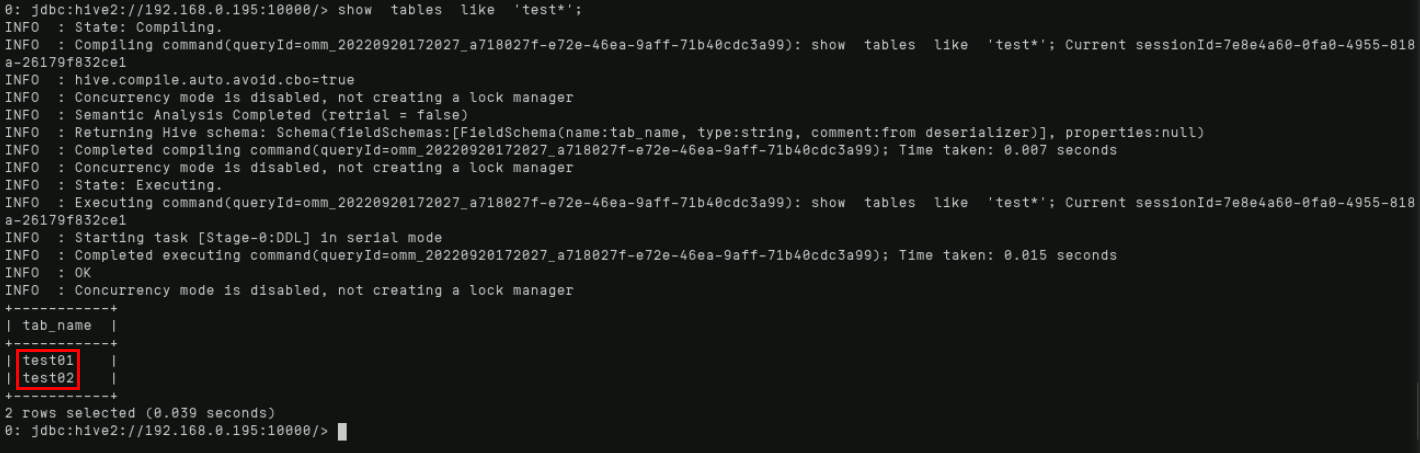
2.6.2.简单查询
Limit(典型的查询会返回多行数据,Limit子句用于限制返回的行数。)
执行命令:
select * from test02 limit 2;
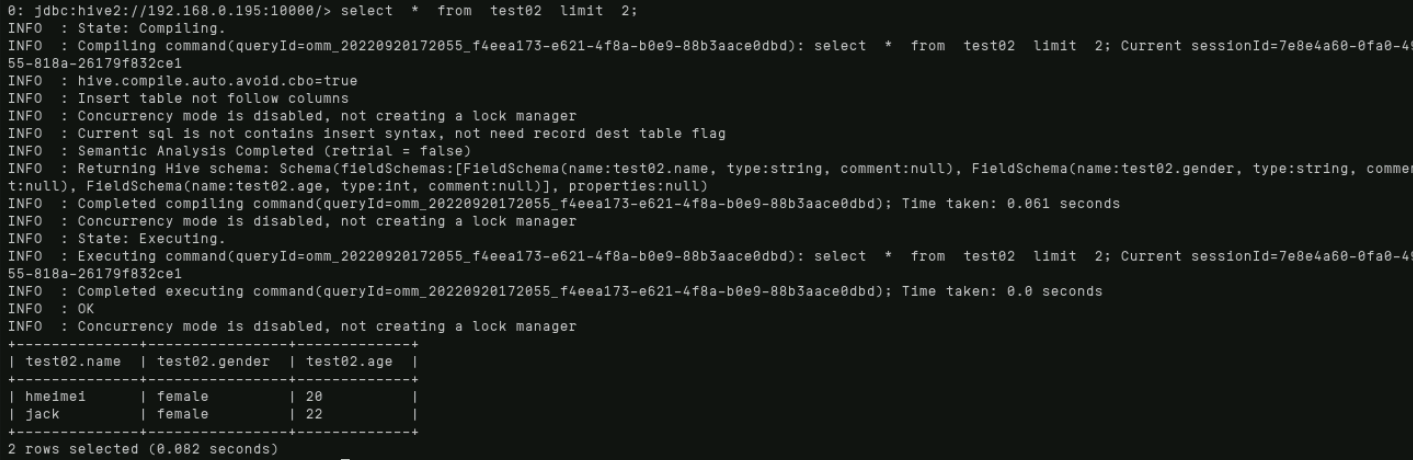
Where(使用where子句,将不满足条件的行过滤掉,where子句紧随from子句后面。)
执行命令:
select * from test02 where gender ='male' limit 2;

Order by(order by为全局排序,后面可以有多列进行排序,默认按字典排序。)
执行命令:
select * from test02 where gender ='female' order by age limit 2;

2.6.3.复杂查询
首先通过“ctrl+c”退出hive模式,之后在本地使用“vi”编辑数据文件test03.txt,具体内容如下:
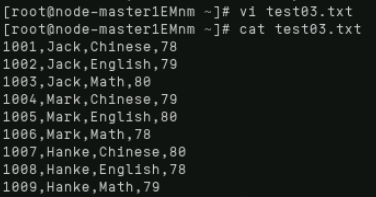
将刚刚新增的数据文件上传至HDFS。
执行命令:
hdfs dfs -put test03.txt /user/test01/

使用“beeline”命令再次进入Hive模式,创建测试用表,具体命令如下:
create external table test03(id int,name string ,subject string,score float) row format delimited fields terminated by ',' stored as textfile ;
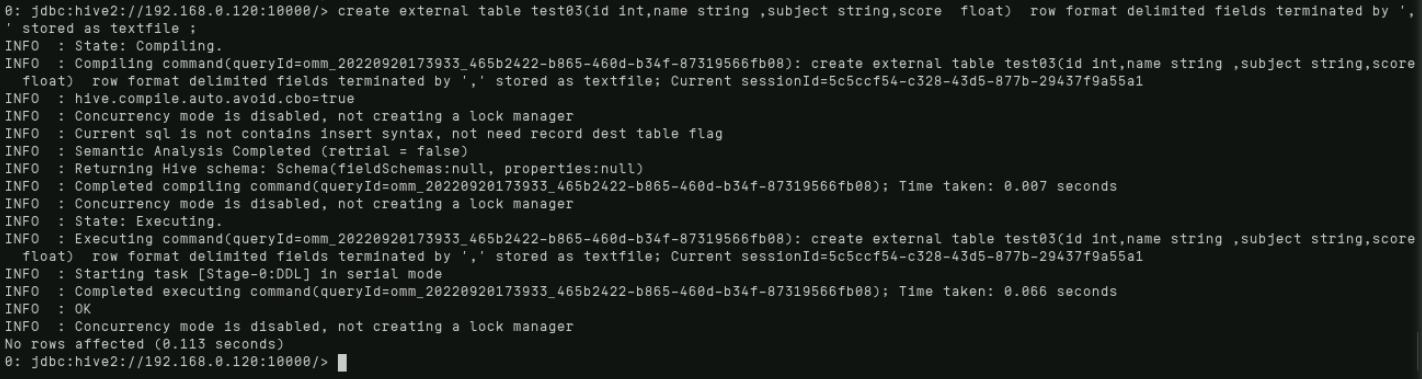
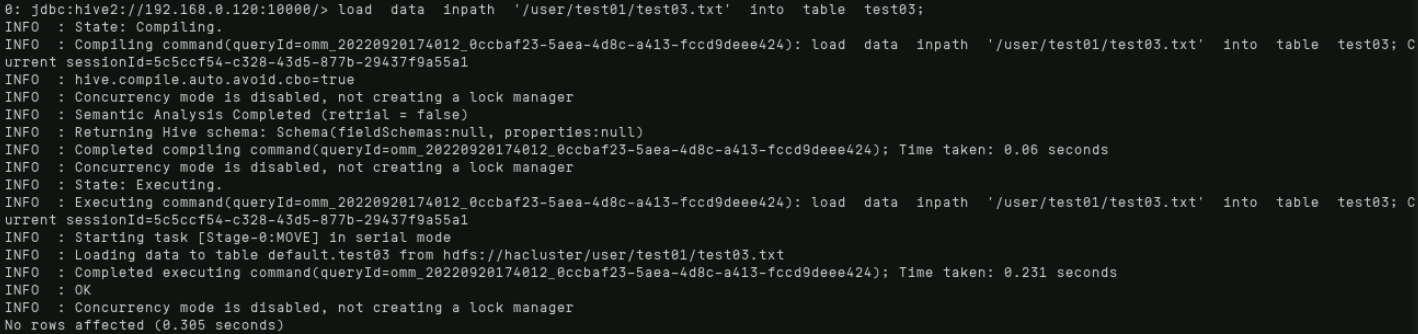
使用如下命令将数据导入至对应测试用表中:
load data inpath '/user/test01/test03.txt' into table test03;
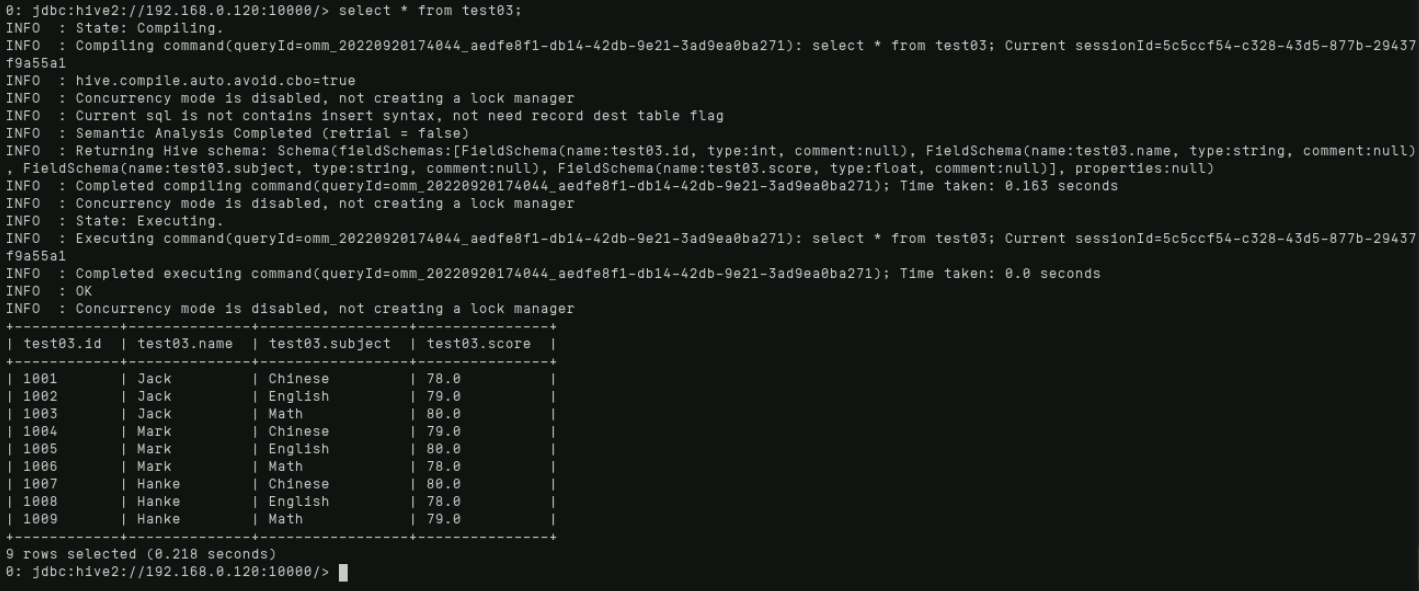
select * from test03;
Sum(将某列进行累加(如果某行的列的为null则忽略))
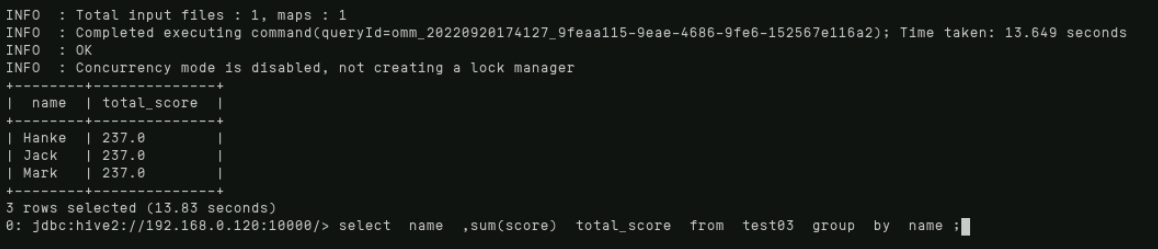
通过执行如下命令完成测试用例中学生成绩的汇总统计:
select name ,sum(score) total_score from test03 group by name ;
求出学生总成绩后,过滤出总分大于230的学生,具体命令如下:
select name ,sum(score) total_score from test03 group by name having total_score > 230;
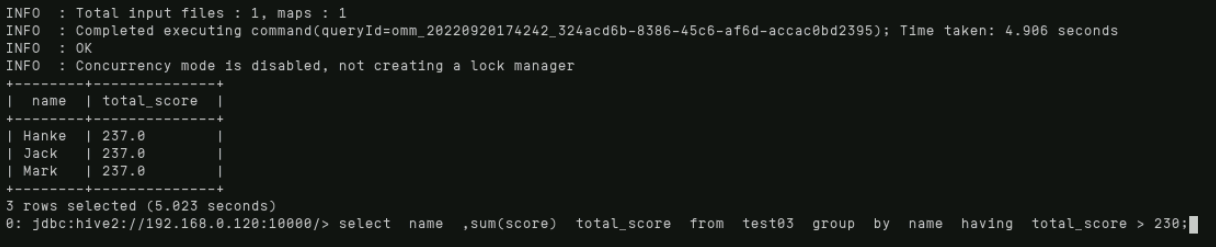
Max(获取组内某字段最大值(null自动忽略))
查看每门课程的最高分,具体命令如下:
select subject,max(score) from test03 group by subject;
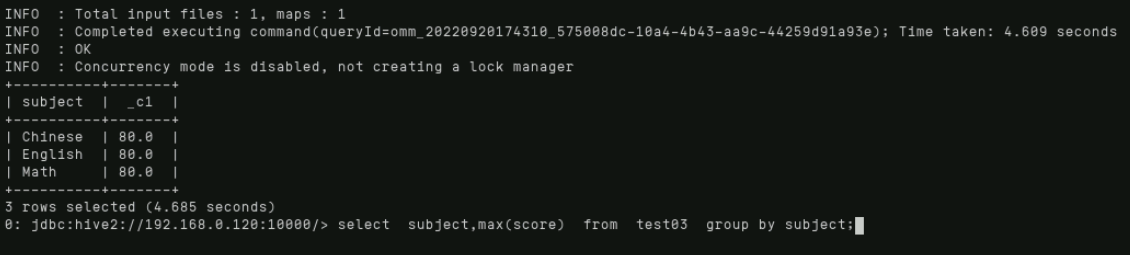
Count(统计有效行(非null))
统计每门课有多少人参加考试,具体命令如下:
select subject,count(1) from test03 group by subject;
2.7.Hadoop分析
2.7.1.准备Hadoop样例程序
具体操作如下:
登录主用ECS“master1”,输入如下命令下载hadoop样例程序:
wget https://dist.apache.org/repos/dist/release/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz

通过“tar”命令解压下载好的样例程序安装包,具体命令如下:
tar -zxvf hadoop-3.2.4.tar.gz
2.7.2.准备Hadoop数据文件
通过“vi”编辑两个数据文件,即wordcount1.txt和wordcount2.txt,具体操作命令如下:
vi wordcount1.txt

vi wordcount2.txt
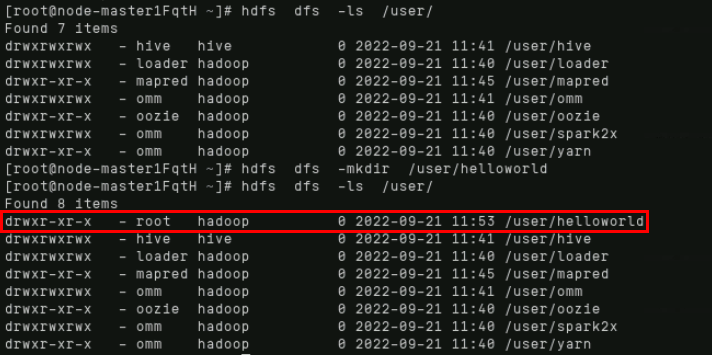
在hdfs根目录的user文件夹下创建helloworld文件夹,首先查看user下的内容,然后创建,再使用ls命令查看,可以看到出现了helloworld文件夹:
hdfs dfs -ls /user/
hdfs dfs -mkdir /user/helloworld
hdfs dfs -ls /user/
同理创建input文件夹:
hdfs dfs -mkdir /user/input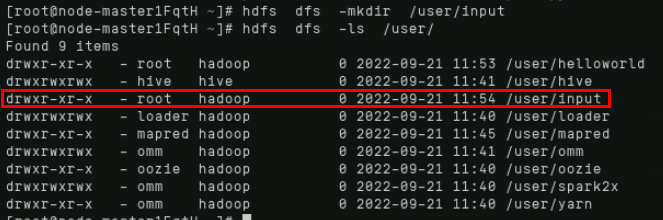
通过“put”命令,将之前下载好的样例程序上传至刚创建好的helloworld文件夹,具体命令如下:
hdfs dfs -put hadoop-3.2.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.4.jar /user/helloworld/

同理将之前编辑好的wordcount1.txt和wordcount2.txt上传至刚创建好的input文件夹,具体命令如下:
hdfs dfs -put wordcount1.txt /user/input/
hdfs dfs -cat /user/input/wordcount1.txt

hdfs dfs -put wordcount2.txt /user/input/
hdfs dfs -cat /user/input/wordcount2.txt

2.7.3.通过MRS界面提交分析作业任务
在MRS控制台左侧导航栏选择“集群列表 > 现有集群”,单击名称为“mrs_test”的集群。
在集群信息页面选择“作业管理”页签,单击“添加”,进入添加作业页面,居然操作如下:
“作业类型”选择“MapReduce”;
“作业名称”填写“wordcount”;
“程序执行路径”单击HDFS,选择刚刚在HDFS上传的hadoop样例程序,具体路径为:
/user/helloworld/hadoop-mapreduce-examples-3.2.4.jar;
“执行程序参数”配置为:
wordcount hdfs://hacluster/user/input/ hdfs://hacluster/user/output/ 。output为输出路径(请设置为一个不存在的目录);
“服务配置参数”不配置。


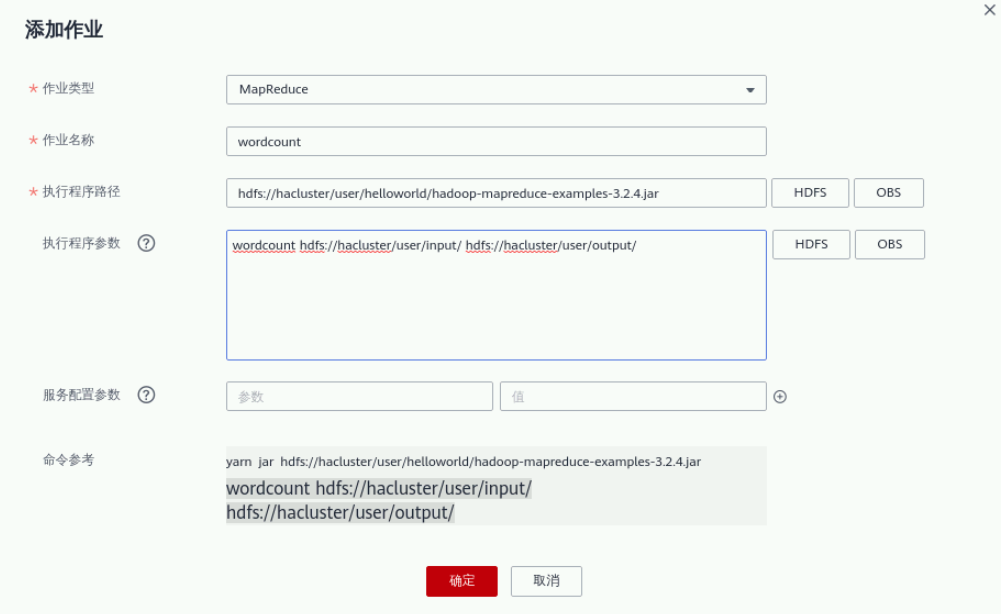
单击“确定”,提交作业。
作业提交成功后默认为“已接受”状态,不需要用户手动执行作业。
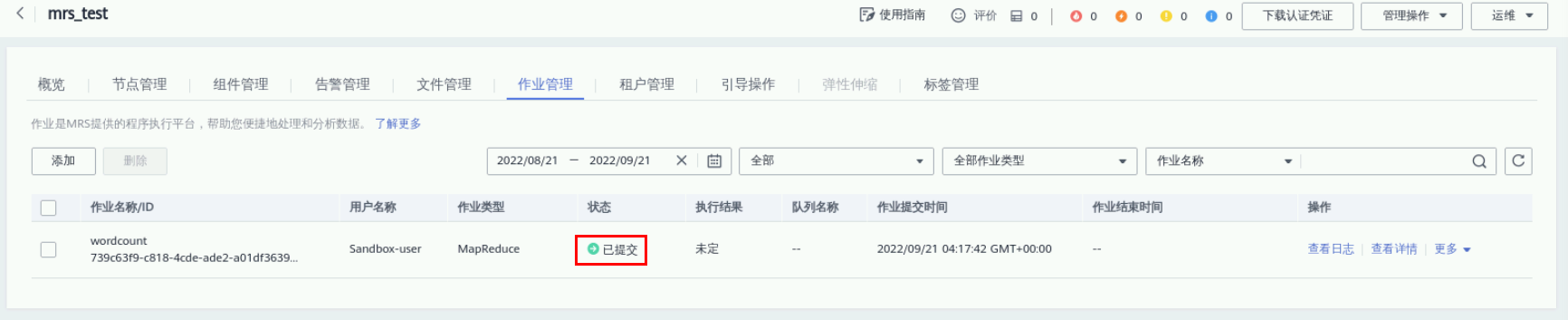
进入“作业管理”页面,查看作业执行状态及日志,稍等几分钟后可以看到作业已执行成功。

此时返回Cloudshell界面,通过hdfs查询命令查看作业执行结果所对应的输出文件夹output,具体操作如下:
执行ls命令查看output文件夹下存在的输出文件:
hdfs dfs -ls /user/output

执行cat命令查看part-r-00000文件内的分析结果:
hdfs dfs -cat /user/output/part-r-00000

至此实验内容全部完成。
